HERE Workspace & Marketplace 2.11 release

Highlights
Marketplace consumer - fully complete subscriptions online (not available in China)
When browsing a listing where standard pricing and terms are visible, data consumers can click-through the entire subscription process online without offline negotiations with the providers. This simplifies and accelerates data access and the buying process. After the subscription process is completed successfully, you will start seeing the subscription billing on your monthly platform invoice.
Efficiently query Index storage using International Organization for Standardization (ISO) country codes
This release contains updates to the Index layer Query API which enable you to efficiently query data by country in addition to your other query parameters. You can now include an ISO country code in the query parameter thereby simplifying your query request. This change represents a usability enhancement, which improves the Index storage experience. Developers using OLP China will see query results limited to ISO country codes specific to that region: CHN, HKG, MAC.
New data connector available - more easily integrate Volatile data and Flink pipelines
The Flink connector integrates proprietary catalogs and layers with the industry-standard format of Flink (TableSource), allowing you to leverage search, filter, map, and sort capabilities offered by the standard Apache Flink framework. In addition to previously released functions, the Flink connector now supports Volatile layer reads and writes for metadata and data.
See Flink Connector documentation for more information about all supported layer types, data formats and operations.
With these updates, you can spend less time writing low-level pipeline/data integration code and more time on your use case-specific business logic.
Location referencing - encode events in an industry standard format
In addition to adding TISA TMC/TPEG2-encoded traffic data decoding capability to the Location Library, you are now also able to encode the events and their locations from Stable Topology Segment IDs to the TISA TMC/TPEG2 format so that you can send this data to external systems in an industry standard format (e.g. to traffic broadcast systems).
Simplified attribute access - additional HERE Map Content attributes available
As noted in the 2.10 release, we will continue to iteratively compile HERE Map Content attributes into the Optimized Map for Location Library enabling fast and simplified direct access to these attributes via the Location Library. In this release, we added the remaining attributes from the Road Attributes layer from the HERE Map Content catalog. Example attributes include Access Characteristics and more. For more detail on the added attributes, please see: HERE Map Content- Road Attributes layer
Unified data inspection experience - find partitions on a map or choose from a list of partitions
This release comes with a redesigned layer details page to bring a more unified and seamless data inspection experience to the Portal. The Partitions tab has been removed and its functionality has been fully integrated into the Inspect tab.
There are two new toggle buttons in the Data Inspector’s Toolbar (top-left corner).
Click Map view to inspect layers on top of the map. As before, this currently works only with Versioned and Volatile layers that are HERE partitioned and that have a GeoJSON plugin or that are of type GeoJSON.
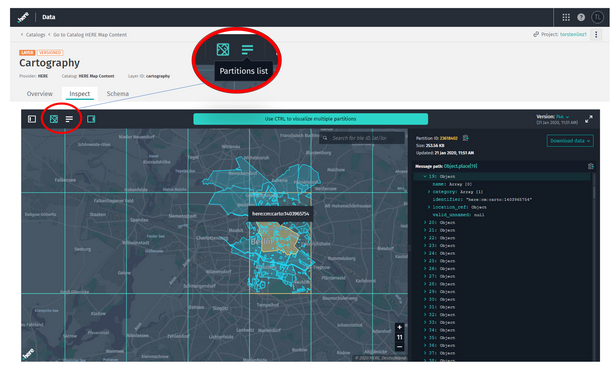
Use the Partitions list button to access a panel that lists all the partitions in a layer. As before in the separate tab, this works for Versioned and Volatile layers, independent of the partitioning scheme or the kind of data they contain. Decoding requires that the data layer is either connected with a Protobuf schema or is of type GeoJSON.
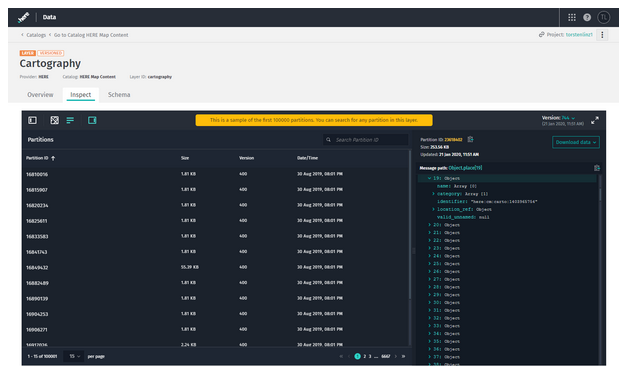
Like before in the separate tab, the new Partitions list panel can only display 100k entries. This is to keep the application performant and responsive. You may still use the search box to search through all partitions in the layer with no limitations.
Changes, Additions and Known Issues
SDK for Java and Scala
To read about updates to the SDK for Java and Scala, please visit the HERE Open Location Platform Changelog.
Web & Portal
Issue: The custom run-time configuration for a Pipeline Version has a limit of 64 characters for the property name and 255 characters for the value.
Workaround: For the property name, you can define a shorter name in the configuration and map that to the actual, longer name within the pipeline code. For the property value, you must stay within the limitation.
Issue: Pipeline Templates can't be deleted from the Portal UI.
Workaround: Use the CLI or API to delete Pipeline Templates.
Issue: In the Portal, new jobs and operations are not automatically added to the list of jobs and operations for a pipeline version while the list is open for viewing.
Workaround: Refresh the Jobs and Operations pages to see the latest job or operation in the list.
Projects & Access Management
Issue: A finite number of access tokens (~ 250) are available for each app or user. Depending on the number of resources included, this number may be smaller.
Workaround: Create a new app or user if you reach the limitation.
Issue: Only a finite number of permissions are allowed for each app or user in the system across all services. It will be reduced depending on the inclusion of resources and types of permissions.
Issue: All users and apps in a group are granted permissions to perform all actions on any pipeline associated with that group. There is no support for users or apps with limited permissions. For example, you cannot have a reduced role that can only view pipeline status, but not start and stop a pipeline.
Workaround: Limit the users in a pipeline's group to only those users who should have full control over the pipeline.
Issue: When updating permissions, it can take up to an hour for changes to take effect.
Issue: Projects and all resources in a Project are designed for use only in Workspace and are unavailable for use in Marketplace. For example, a catalog created in a Platform Project can only be used in that Project. It cannot be marked as "Marketplace ready" and cannot be listed in the Marketplace.
Workaround: Do not create catalogs in a Project when they are intended for use in both Workspace and Marketplace.
Data
Issue: Versions of the Data Client Library prior to 2.9 did not compress or decompress data correctly per configurations set in Stream layers. We changed this behavior in 2.9 to strictly adhere to the compression setting in the Stream layer configuration but when doing so, we broke backward compatibility wherein data ingested and consumed via different Data Client Library versions will likely fail. The Data Client Library will throw an exception and, depending upon how your application handles this exception, could lead to an application crash or downstream processing failure. This adverse behavior is due to inconsistent compression and decompression of the data driven by the different Data Client Library versions. 2.10 introduces more tolerant behavior which correctly detects if stream data is compressed and handles it correctly.
Workaround: In the case where you are using compressed Stream layers and streaming messages smaller than 2MB, use the 2.8 SDK until you have confirmed that all of your customers are using at least the 2.10 SDK where this Data Client Library issue is resolved, then upgrade to the 2.10 version for the writing aspects of your workflow.
Issue: The changes released with 2.9 (RoW) and with 2.10 (China) to add OrgID to Catalog HRNs and with 2.10 (Global) to add OrgID to Schema HRNs could impact any use case (CI/CD or other) where comparisons are performed between HRNs used by various workflow dependencies. For example, requests to compare HRNs that a pipeline is using vs what a Group, User or App has permissions to will result in errors if the comparison is expecting results to match the old HRN construct. With this change, Data APIs will return only the new HRN construct which includes the OrgID (e.g. olp-here…) so a comparison between the old HRN and the new HRN will be unsuccessful.
- Also: The resolveDependency and resolveCompatibleDependencies methods of the Location Library may stop working in some cases until this known issue is resolved.
- Reading from and writing to Catalogs using old HRNs is not broken and will continue to work for (6) months.
- Referencing old Schema HRNs is not broken and will work into perpetuity.
Workaround: Update any workflows comparing HRNs to perform the comparison against the new HRN construct, including OrgID.
Issue: Searching for a schema in the Portal using the old HRN construct will return only the latest version of the schema. Portal currently will not show older versions tied to the old HRN.
Workaround: Search for schemas using the new HRN construct OR lookup older versions of schemas by old HRN construct using the OLP CLI.
Issue: Visualization of Index layer data is not yet supported.
Pipelines
Issue: For Stream (Flink) pipelines, the Splunk logs do not contain the logs specified inside the executable Jar file.
Workaround: Redirect the standard out and error back to System.out and System.err by adding the below lines as the first thing in the main method:
System.setOut(new PrintStream(new FileOutputStream(FileDescriptor.out)));
System.setErr(new PrintStream(new FileOutputStream(FileDescriptor.err)));
Issue: A pipeline failure or exception can sometimes take several minutes to respond.
Issue: Pipelines can still be activated after a catalog is deleted.
Workaround: The pipeline will fail when it starts running and will show an error message about the missing catalog. Re-check the missing catalog or use a different catalog.
Issue: If several pipelines are consuming data from the same Stream layer and belong to the same Group (pipeline permissions are managed via a Group), then each of those pipelines will only receive a subset of the messages from the stream. This is because, by default, the pipelines share the same Application ID.
Workaround: Use the Data Client Library to configure your pipelines to consume from a single stream: If your pipelines/applications use the Direct Kafka connector, you can specify a Kafka Consumer Group ID per pipeline/application. If the Kafka consumer group IDs are unique, the pipelines/applications will be able to consume all the messages from the stream.
If your pipelines use the HTTP connector, we recommend you to create a new Group for each pipeline/application, each with its own Application ID.
Issue: The Pipeline Status Dashboard in Grafana can be edited by users. Any changes made by the user will be lost when updates are published in future releases because users will not be able to edit the dashboard in a future release.
Workaround: Duplicate the dashboard or create a new dashboard.
Issue: For Stream pipeline versions running with the high-availability mode, in a rare scenario, the selection of the primary Job Manager fails.
Workaround: Restart the stream pipeline.
Location Services
Issue: Lack of usage reporting for location services launched in 2.10 (Routing, Search, Transit, and Vector Tiles).
Workaround: Raise a request via Contact us to get details of your usage report.
Marketplace
Issue: Users do not receive stream data usage metrics when reading or writing data from Kafka Direct.
Workaround: When writing data into a Stream layer, you must use the ingest API to receive usage metrics. When reading data, you must use the Data Client Library, configured to use the HTTP connector type, to receive usage metrics and read data from a Stream layer.
Issue: When the Technical Accounting component is busy, the server can lose usage metrics.
Workaround: If you suspect you are losing usage metrics, contact HERE technical support for assistance rerunning queries and validating data.
SDK for Python
Fixed: Windows is now supported along with MacOS and Linux distributions.
Changed: The SDK for Python can now be installed using your own docker build as well. This enables a simpler automated build that executes several command-line instructions in succession. Refer to the Build Your Own Docker section in the SDK for Python Setup Guide for further details.
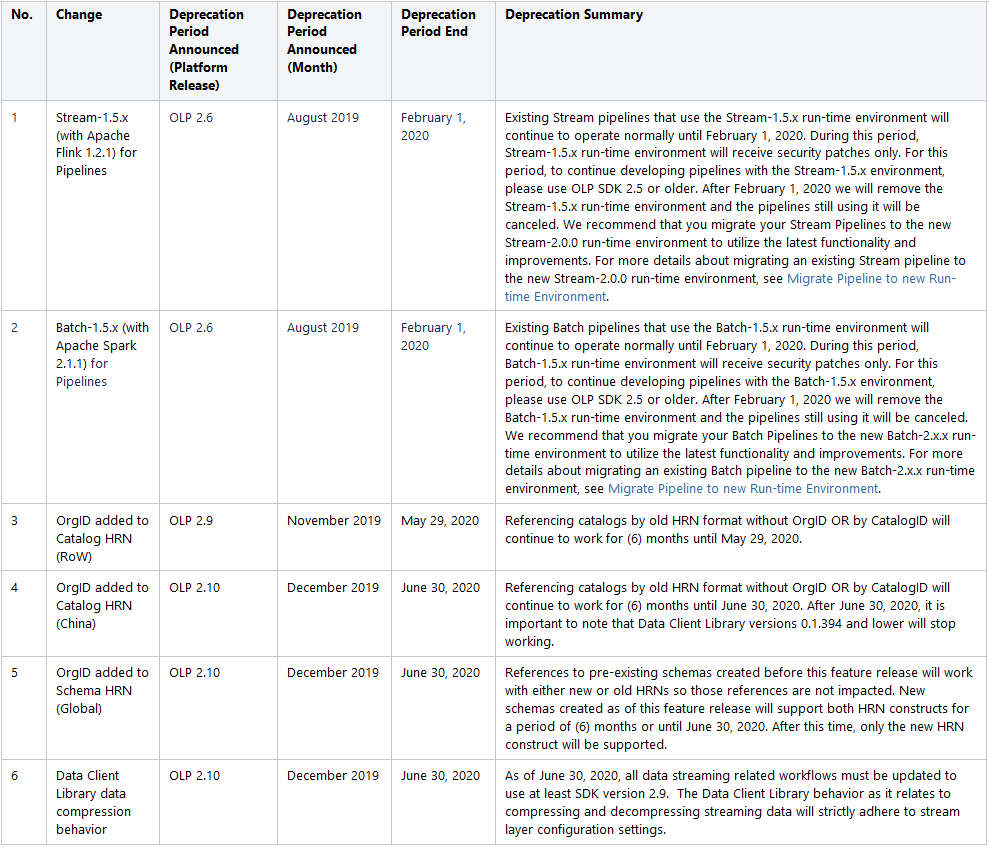
Summary of active deprecation notices across all components
Have your say
Sign up for our newsletter
Why sign up:
- Latest offers and discounts
- Tailored content delivered weekly
- Exclusive events
- One click to unsubscribe