HERE Workspace & Marketplace 2.7 release

Highlights for this release
Automatic Recovery of Stream Pipelines from Failed Flink JobManager
Stream Pipelines using the stream-2.0.x environment can now be run in the High-Availability mode to automatically recover from a failed Flink JobManager.
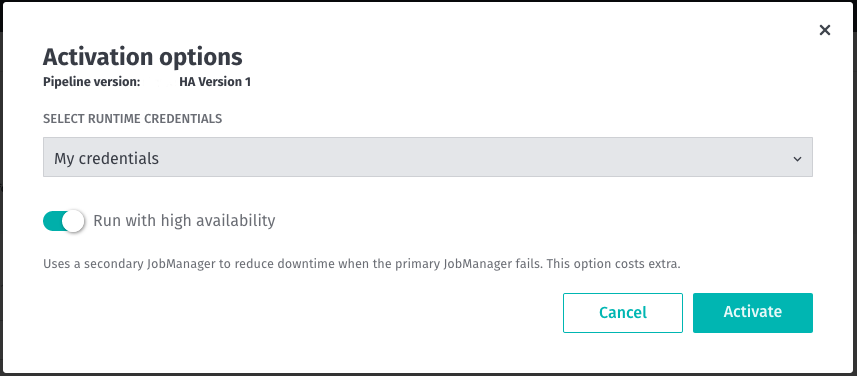
High-Availability mode reduces the downtime during processing to near-zero and is beneficial for the time-sensitive Stream data processing. In this mode, two (2) Flink JobManagers are created for a Stream pipeline job so that when the primary JobManager fails, the secondary JobManager will continue to run the pipeline job.
This feature is optional and introduces additional cost for the extra resources. See Stream Pipeline Best Practices for more details.
Use Flink Dashboard to troubleshoot currently Running Stream Pipelines
Flink Dashboard is now available to view execution and performance details of a Stream pipeline job when it is in the Running state.
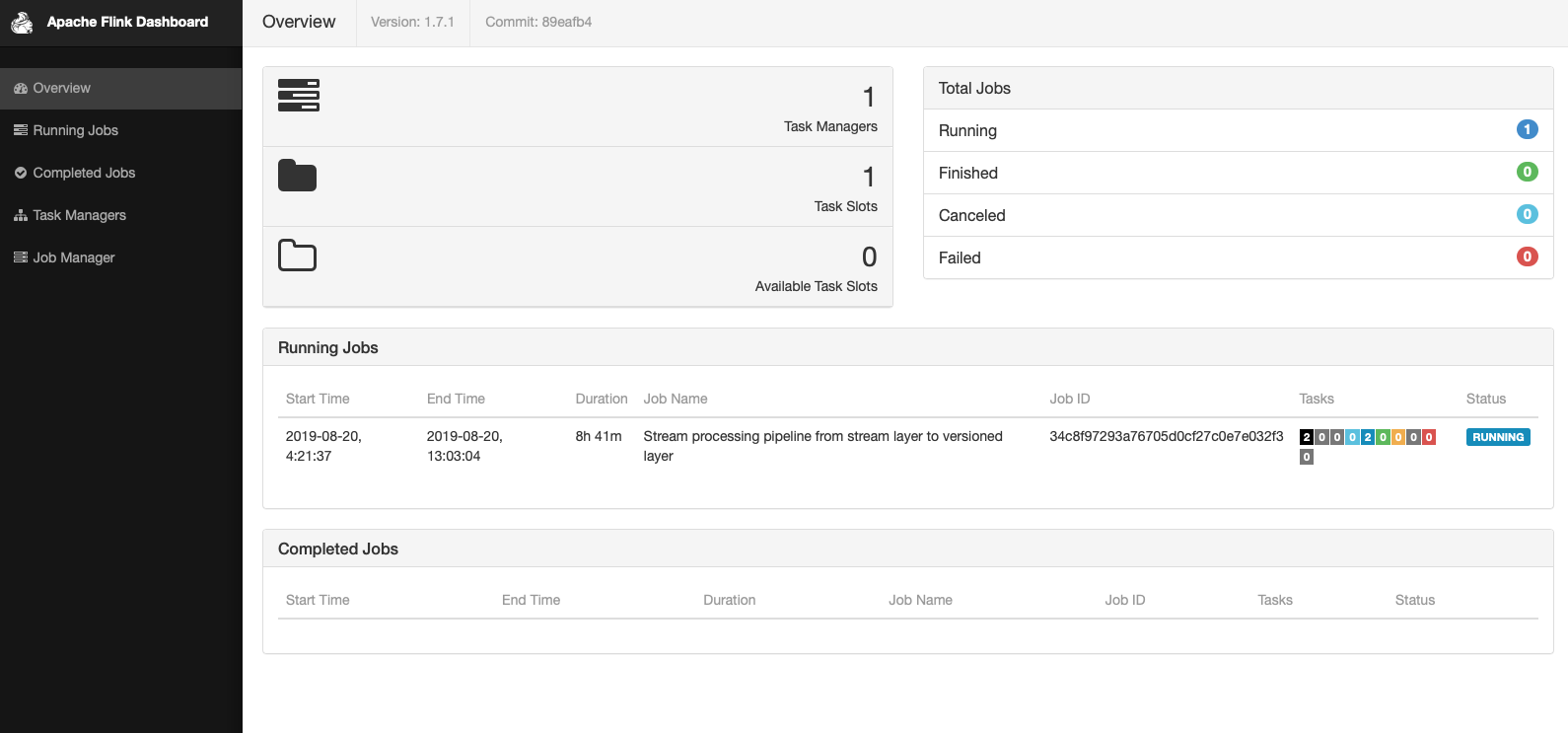
This functionality is available for Stream-1.5.0 and Stream-2.x.x run-time environments. Access to these details helps in optimizing and troubleshooting Stream pipelines. Each Stream pipeline job in the Running state will be associated with a link that will open the Flink Dashboard in a new browser window/tab.
When the Stream pipeline job is canceled or fails, the Flink Dashboard will no longer be available for that job.
Delete data from Index Layers
With this release, you can delete index layer metadata and data directly by using RSQL queries. This functionality is supported by the following Data interfaces: API, Data Client Library, CLI.
Simple switching to Japanese and Chinese languages in the portal
The portal can now be viewed in English, Japanese, and Chinese. The language selector can be found in the footer of platform.here.com

Changes, Additions and Known Issues
SDK for Java and Scala
To read about updates to the SDK for Java and Scala, please visit the SDK Release Notes.
Web & Portal
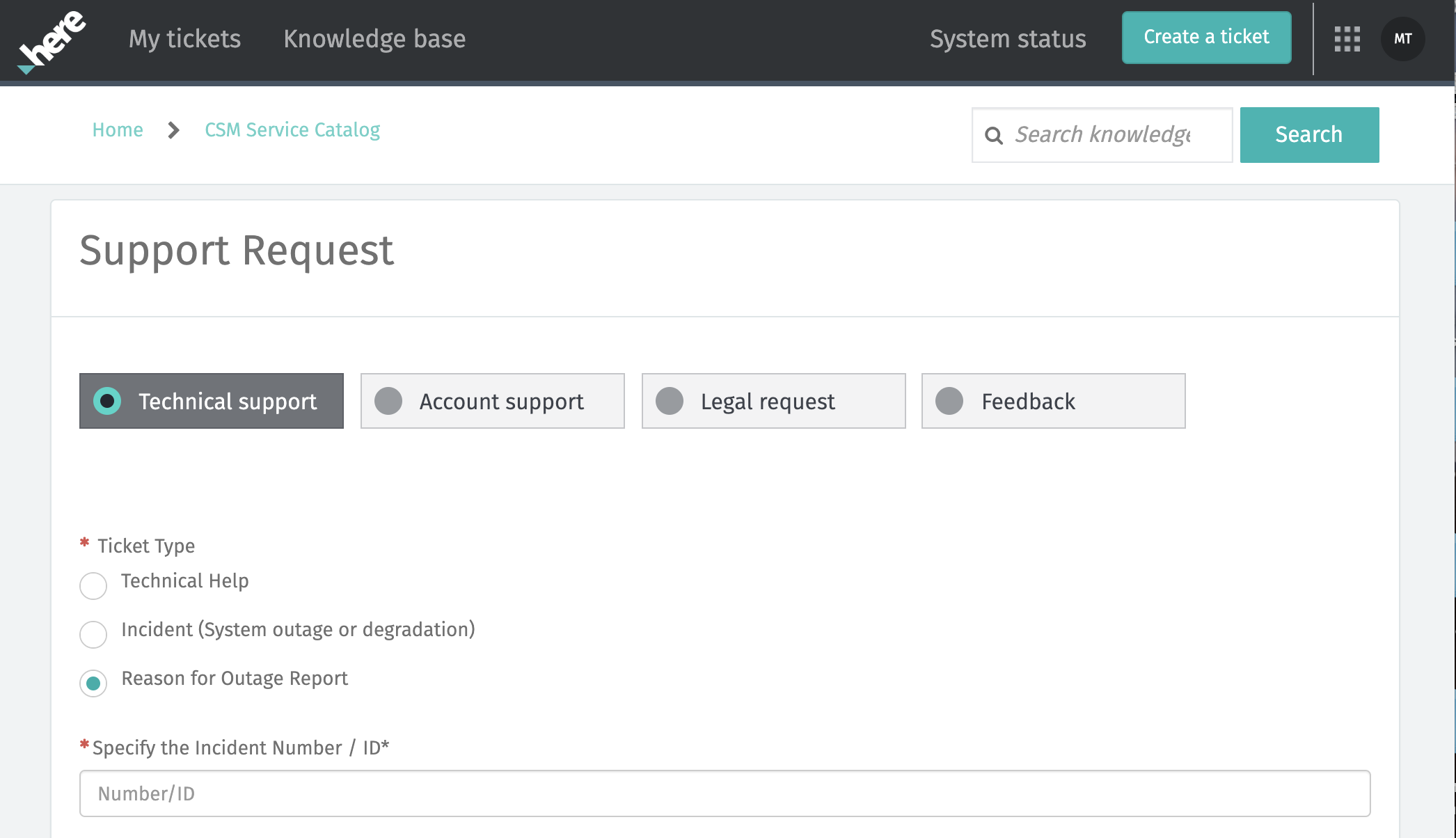
Added: Request root cause analysis reports through the support portal
(not applicable for OLP China)
Customers with a platinum level support plan may request a written root cause analysis report for any priority 1 or 2 incident. It is now possible to request these reports through the HERE Support Portal. Visit platform.here.com/contact-us and raise a technical support ticket. The option for a root cause analysis report request is there. Reports are provided within 10 business days of the request.
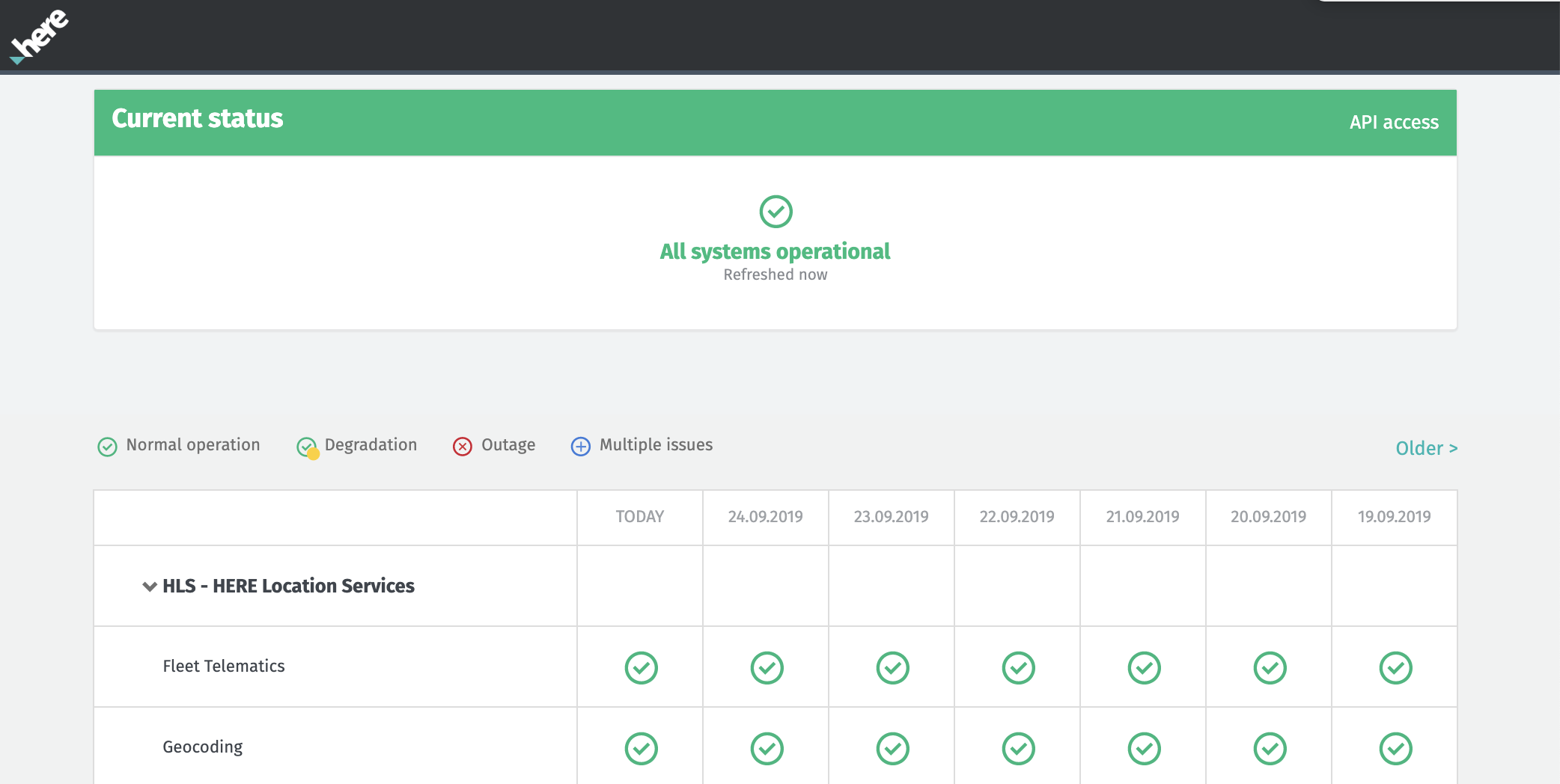
Added: It's now possible to use 'service' as a query parameter when making calls to the HERE Status API. For details, see the API Access page on status.here.com.
Added: HERE Location Services (HLS) have been added alongside Open Location Platform Services (OLP) on status.here.com.
Issue: The custom run-time configuration for a Pipeline Version has a limit of 64 characters for the property name and 255 characters for the value.
Workaround: For the property name, you can define a shorter name in the configuration and map that to the actual, longer name within the pipeline code. For the property value, you must stay within the limitation.
Issue: Pipeline Templates can't be deleted from the Portal UI.
Workaround: Use the CLI or API to delete Pipeline Templates.
Issue: In the Portal, new jobs and operations are not automatically added to the list of jobs and operations for a pipeline version while the list is open for viewing.
Workaround: Refresh the Jobs and Operations pages to see the latest job or operation in the list.
Account & Permissions
Issue: A finite number of access tokens (~ 250) are available for each app or user. Depending on the number of resources included, this number may be smaller.
Workaround: Create a new app or user if you reach the limitation.
Issue: Only a finite number of permissions are allowed for each app or user in the system across all services. It will be reduced depending on the inclusion of resources and types of permissions.
Issue: All users and apps in a group are granted permissions to perform all actions on any pipeline associated with that group. There is no support for users or apps with limited permissions. For example, you cannot have a reduced role that can only view pipeline status, but not start and stop a pipeline. Limit the users in a pipeline's group to only those users who should have full control over the pipeline.
Issue: When updating permissions, it can take up to an hour for changes to take effect.
Data
Known Issues: Partition list information normally available within the Layer/Partitions tab of the Portal UI is not displaying correctly for newer Volatile layers created after September 10. This known issue is actively being worked on and should be resolved shortly.
Temporary workaround: To get partition list information for new volatile layers created after September 10, please use the appropriate CLI command with one of the following parameters:
--modified-since 2018
OR
--modified-since <time-of-interest>
Example: olp catalog layer partition list <your-catalog-HRN> <your-volatile-layer-ID> --modified-since 2018
Issue: Catalogs not associated with a realm are not visible in OLP.
Issue: Visualization of Index Layer data is not yet supported.
Issue: When you use the Data API or Data Library to create a Data Catalog or Layer, the app credentials used do not automatically enable the user who created those credentials to discover, read, write, manage, and share those catalogs and layers.
Workaround: After the catalog is created, use the app credentials to enable sharing with the user who created the app credentials. You can also share the catalog with other users, apps, and groups.
Pipelines
Issue: Given a Stream pipeline version running with the High-Availability mode enabled, when the pipeline version is viewed in the Portal and is paused or canceled or a new pipeline version is created within the same pipeline, then the High-Availability mode remains enabled during Resume, re-Activation of the existing pipeline version or during the Activation of the new pipeline version. The correct behavior is that the high-availability mode is disabled by default. We are working on a fix.
Workaround: Uncheck the box "Run with high-availability" during Activation and Resume when operating via Portal. Or, consider using the CLI or Pipeline API.
Issue: A pipeline failure or exception can sometimes take several minutes to respond.
Issue: Pipelines can still be activated after a catalog is deleted.
Workaround: The pipeline will fail when it starts running and will show an error message about the missing catalog. Re-check the missing catalog or use a different catalog.
Issue: If several pipelines are consuming data from the same stream layer and belong to the same Group (pipeline permissions are managed via a Group), then each of those pipelines will only receive a subset of the messages from the stream. This is because, by default, the pipelines share the same Application ID.
Workaround: Use the Data Client Library to configure your pipelines to consume from a single stream: If your pipelines/applications use the Direct Kafka connector, you can specify a Kafka Consumer Group ID per pipeline/application. If the Kafka consumer group IDs are unique, the pipelines/applications will be able to consume all the messages from the stream.
If your pipelines use the HTTP connector, we recommend you to create a new Group for each pipeline/application, each with its own Application ID.
Issue: The Pipeline Status Dashboard in Grafana can be edited by users. Any changes made by the user will be lost when updates are published in future releases because users will not be able to edit the dashboard in a future release.
Workaround: Duplicate the dashboard or create a new dashboard.
Issue: For Stream pipeline versions running with the high-availability mode, in a rare scenario, the selection of the primary Job Manager fails.
Workaround: Restart the stream pipeline.
Marketplace
Changed: When a catalog is marked marketplace-ready, you can continue to add and/or remove layers from the catalog even after your catalog has active subscriptions. This enables you to be fully in control of your data offerings in the marketplace.
Added: You can offer evaluation data (free of charge) for promotion or market research purposes in the marketplace. When publishing an evaluation data listing, the connection fees are waived.
When a Marketplace user discovers your evaluation data listing, they can self-subscribe to the data with no subscription fees. For more details, see the Marketplace Provider User Guide or the Marketplace Consumer User Guide
Issue: Users do not receive stream data usage metrics when reading or writing data from Kafka Direct.
Workaround: When writing data into a stream layer, you must use the ingest API to receive usage metrics. When reading data, you must use the Data Client Library, configured to use the HTTP connector type, to receive usage metrics and read data from a stream layer.
Issue: When the Splunk server is busy, the server can lose usage metrics.
Workaround: If you suspect you are losing usage metrics, contact HERE technical support for assistance rerunning queries and validating data.
Notebooks
Deprecated: OLP Notebooks has been deprecated, please refer to the advantages and enhancements offered in the new OLP SDK for Python instead. Download your old notebooks and refer to the Zeppelin Notebooks Migration Guide for further instructions.
OLP SDK for Python
Issue: Currently, only MacOS and Linux distributions are supported.
Workaround: If you are using Windows OS, we recommend that you use a virtual machine.

Have your say
Sign up for our newsletter
Why sign up:
- Latest offers and discounts
- Tailored content delivered weekly
- Exclusive events
- One click to unsubscribe