- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
Common Issues
- Common Issues
- General & local issues
- Python - Entry Point not found
- Sparkmagic extension
skipna=true - Pyspark kernel
TypeError - Cell error
requirement failed: Session isn't active. - Error creating conda environment because of python-geohash dependency
- Error using data client library:
No FileSystem for scheme: olp - Error reading indexed layers with parquet using data client library
- EMR Issues
- HERE Data SDK for Python-Core issues
- General & local issues
General & local issues
Python Entry Point not found
While installing the SDK using the sdk_setup.py if you are facing any error like Python.exe - Entry Point not found, follow these steps:
-
conda activate
-
conda update python
Sparkmagic extension skipna=true
When you display data contains NaT values, you will see a warning message below the paragraph:
/usr/local/lib/python3.6/site-packages/autovizwidget/widget/utils.py:50: FutureWarning:
A future version of pandas will default to `skipna=True`. To silence this warning, pass `skipna=True|False` explicitly.
This warning message does not affect the behavior of your notebook.
This is a sparkmagic problem and will be solved in a future pandas version, when the default value of skpna parameter is true for the pandas.api.types.infer_dtype method.
Workaround: No action required as this does not affect the behavior of the notebooks.
Pyspark kernel TypeError
Pyspark kernel TypeError: object of type 'NoneType' has no len(). The first time (or after a kernel restarting) you use the %%sql magic command to pass the data from spark to local python, such as this:
%%sql -o nodes
select * from nodes
You will get this error:
Traceback (most recent call last):
File "/usr/lib64/python2.7/SocketServer.py", line 295, in _handle_request_noblock
self.process_request(request, client_address)
File "/usr/lib64/python2.7/SocketServer.py", line 321, in process_request
self.finish_request(request, client_address)
File "/usr/lib64/python2.7/SocketServer.py", line 334, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "/usr/lib64/python2.7/SocketServer.py", line 649, in __init__
self.handle()
File "/usr/spark-2.4.0/python/lib/pyspark.zip/pyspark/accumulators.py", line 266, in handle
poll(authenticate_and_accum_updates)
File "/usr/spark-2.4.0/python/lib/pyspark.zip/pyspark/accumulators.py", line 241, in poll
if func():
File "/usr/spark-2.4.0/python/lib/pyspark.zip/pyspark/accumulators.py", line 254, in authenticate_and_accum_updates
received_token = self.rfile.read(len(auth_token))', "TypeError: object of type 'NoneType' has no len()"]
This error was already mitigated by the community and is released in the spark 2.4.1. Further investigation is needed to find a definitive solution, as the mitigation from the community will disappear in Spark 3, according to the community decision.
The current spark version we provide is 2.4.0.
Workaround: Re-run the problematic paragraph.
Cell error requirement failed: Session isn't active.
If you get the following error:
An error was encountered:
Invalid status code '400' from http://livy:8998/sessions/[#]/statements/[#] with error playload: "requirement failed: Session isn't active."
It is because your livy/spark-driver session is being terminated for some reason.
Check the livy logs in the folder ~/livy/logs/.
You can also check the spark executor resources in the Spark-UI for local deployment which runs on http://localhost:4040/executors/. Using emr you can check it on http://${master_dns}:4040/executors/.
Error creating conda environment because of python-geohash dependency
MacOS
Follow these steps if you are getting an error related with gcc or xcode (xcrun).
In your terminal, install the xcode-select by executing this command:
xcode-select --install
Select Install and Agree buttons and wait a few minutes until the installation process completes.
Now, execute the following command:
sudo installer -pkg /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg -target /
Note
Ensure the .pkg version is the same you have installed in that path.
For more details about the issue, click here.
Try the conda environment installation again.
Centos
For Centos, it is necessary to install the libsasl2-devel package for the python-geohash dependency.
Execute:
sudo yum upgrade python-setuptools
sudo yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel
For more details about the issue, refer here.
Try the conda environment installation again.
Error using data client library: No FileSystem for scheme: olp
If you get an exception like this using the data client library:
java.io.IOException: No FileSystem for scheme: olp
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2660)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2667)
...
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
at com.here.platform.data.client.spark.internal.IndexDataFrameReaderImpl.load(IndexDataFrameReaderImpl.scala:93)
... 56 elided
Specify the property "spark.hadoop.fs.olp.impl" with the value "com.here.platform.data.client.hdfs.DataServiceHadoopFileSystem" in the Spark configuration:
{
"driverMemory": "2G",
...,
"conf": {
...,
"spark.hadoop.fs.olp.impl": "com.here.platform.data.client.hdfs.DataServiceHadoopFileSystem",
...
}
}
You can add it into the Sparkmagic configuration file $HOME/.sparkmagic/config.json in the json field session_configs -> conf -> spark.hadoop.fs.olp.impl. If you are using the Python kernel, you can specify it directly in your jupyter paragraph by using the %%spark config magic command.
Error reading indexed layers with parquet using data client library
If you are using the data client library to read an indexed layer with parquet data, i.e:
%%spark
import com.here.hrn.HRN
import com.here.platform.data.client.spark.IndexDataFrameReader._
import org.apache.spark.sql.{DataFrame, SparkSession}
val catalogHrn = HRN("hrn:here:data::olp-here:olp-sdii-sample-berlin-2")
val layerId = "sample-index-layer"
val bbNorth = 52.7
val bbSouth = 52.3
val bbEast = 13.8
val bbWest = 13.1
val indexLayerQueryString =
s"tileId=INBOUNDINGBOX=($bbNorth, $bbSouth, $bbEast, $bbWest)"
val sdiiDF = spark.
readIndexLayer(catalogHrn, layerId).
format("parquet").
index(query=indexLayerQueryString).
load()
and you get an error like this:
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(Ljava/lang/String;)Ljava/lang/Class;
It is due to a problem in the HERE data client library related to reading of parquet format.
The workaround is to use the olp filesystem directly. This is the same example but using the filesystem:
%%spark
import com.here.hrn.HRN
val catalogHrn = HRN("hrn:here:data::olp-here:olp-sdii-sample-berlin-2")
val layerId = "sample-index-layer"
val bbNorth = 52.7
val bbSouth = 52.3
val bbEast = 13.8
val bbWest = 13.1
val indexLayerQueryString =
s"tile_id=INBOUNDINGBOX=($bbNorth, $bbSouth, $bbEast, $bbWest)"
val parquetLayer = spark.read.parquet(s"olp://$catalogHrn/$layerId/index/${indexLayerQueryString}")
EMR Issues
Issues with EMR are usually related with the resources created in Amazon and the local terraform state.
Error waiting for EMR Cluster state
Occasionally, the deploy might fail related to the cluster state.
Symptoms:
Error: Error applying plan:
1 error(s) occurred:
* aws_emr_cluster.spark-emr-lab: 1 error(s) occurred:
* aws_emr_cluster.spark-emr-lab: Error waiting for EMR Cluster state to be "WAITING" or "RUNNING": TERMINATED_WITH_ERRORS: VALIDATION_ERROR: The VPC/subnet configuration was invalid: No route to any external sources detected in Route Table for Subnet: subnet-00cd6179487d7aa83 for VPC: vpc-0d6c6ceeabdc0908a
Terraform does not automatically rollback in the face of errors. Instead, your Terraform state file has been partially updated with any resources that successfully completed. Please address the error above and apply again to incrementally change your infrastructure.
Possible causes: The root cause is unknown as of today, the circumstances in which this occurs suggests possible connectivity issues between the local machine and AWS.
Solution: Simply invoke the emr-provision command again without modifications
Error creating S3 bucket
Occassionally, when deploying and destroying environments continuously, the deploy might fail stating that it could not create the S3 bucket.
Symptoms:
Error: Error applying plan:
2 error(s) occurred: * aws_s3_bucket.spark-emrlab-bucket: 1 error(s) occurred:
* aws_s3_bucket.spark-emrlab-bucket: Error creating S3 bucket: Error creating S3 bucket spark-emrlab-bucket-castilla, retrying: OperationAborted: A conflicting conditional operation is currently in progress against this resource. Please try again. status code: 409, request id: C9A8FD78A01B7DEE, host id: dr+uOt5aKAdg1/56aBuZwTPDTvw1dw8mWrZi+elmiROol0znbypTIU0tOt9LabsQpfoZAhuMvro=
* aws_emr_cluster.spark-emr-lab: 1 error(s) occurred: * aws_emr_cluster.spark-emr-lab: Error waiting for EMR Cluster state to be "WAITING" or "RUNNING": TERMINATING: BOOTSTRAP_FAILURE: Master instance (i-0403cc5aace11a13a) failed attempting to download bootstrap action 1 file from S3
Terraform does not automatically rollback in the face of errors. Instead, your Terraform state file has been partially updated with any resources that successfully completed. Please address the error above and apply again to incrementally change your infrastructure.
Possible causes: When invoking provision/deprovision repeatedly, some requests against AWS, in particular the ones with s3 buckets are queued and might take some time for them to be completed.
Solution: You can either wait some time (2 hours maximum) or simply change the name suffix you are using, this way you will create different resources. Eventually, the previous resources will be deleted.
The VPC could not be destroyed
When destroying the environment, the VPC is not being destroyed.
Symptoms:
Error: Error applying plan:
1 error(s) occurred:
* aws_vpc.spark-emr-main (destroy): 1 error(s) occurred:
* aws_vpc.spark-emr-main: DependencyViolation: The vpc 'vpc-03745a66e683ce814' has dependencies and cannot be deleted.
status code: 400, request id: 7151dc40-0553-454b-880f-373d3da96e6b
Terraform does not automatically rollback in the face of errors.
Instead, your Terraform state file has been partially updated with
any resources that successfully completed. Please address the error
above and apply again to incrementally change your infrastructure.
Possible causes:
If one of the terraform resources is changed on Amazon, either manually or automatically by other system, the local and remote states become out of sync, and this prevents terraform to destroy the resources. Changes such as manually adding security groups to the VPC is a common cause of this.
Solution:
- You either go to the AWS web console and delete the VPC manually after you see the error, or locate and manually delete the additional resources
- Invoke the deprovision script
How to delete the VPC manually:
- Log into your AWS web console.
- Go to 'Services + VPC + Your VPCs'.
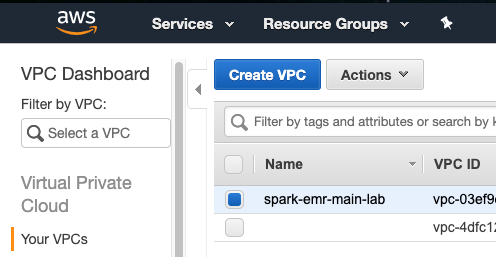
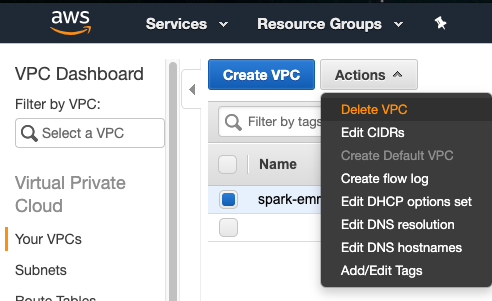
- Check the vpc which name ends with your provided suffix.
- Click on 'Actions', then hit 'Delete VPC'.
IAM instance profile errors
A new environment deploy fails stating that it cannot create the IAM instance profile because it already exists.
Symptoms:
Error: Error applying plan:
1 error(s) occurred:
* aws_iam_instance_profile.spark-emr_profile: 1 error(s) occurred:
* aws_iam_instance_profile.spark-emr_profile: Error creating IAM instance profile spark-emr_profile-lab: EntityAlreadyExists: Instance Profile spark-emr_profile-lab already exists.
status code: 409, request id: 77f84a10-7288-11e9-8338-15cce7c2336c
Terraform does not automatically rollback in the face of errors.
Instead, your Terraform state file has been partially updated with
any resources that successfully completed. Please address the error
above and apply again to incrementally change your infrastructure.
Possible causes:
- If a previous provisioning failed, and the local terraform state got staled
- If a previous deprovisioning failed to delete the resources
Solution: You'll need to delete the resources manually from the AWS console.
- Invoke the destroy script.
- Go to AWS web console
- Go to Services -> IAM - > Roles.

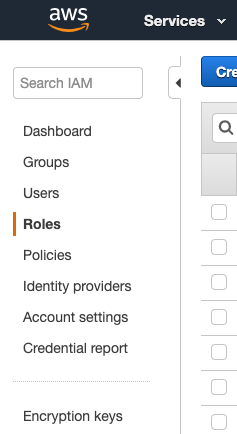
- Search for 'spark' in the text box.
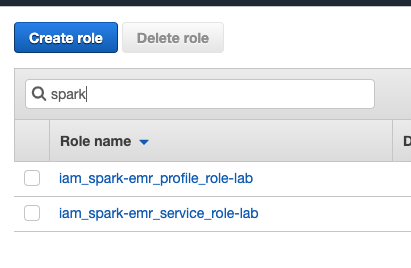
- Delete those with a name similar to the picture.
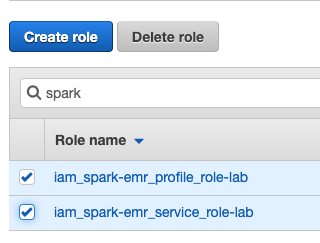
- Invoke the deploy script once more.
Since AWS web console does not show the instance profile unless it is attached to a role, a more reliable way would be to delete the instance profile with awscli:
aws iam list-instance-profiles | grep spark-emr_profileaws iam delete-instance-profile --instance-profile-name <profile name from step #1>
Problems creating the NAT Gateway
Occassionally, the creation of the NAT gateway might fail.
Symptoms:
Error: Error applying plan:
1 error(s) occurred:
* aws_nat_gateway.spark-emr-nat-gw: 1 error(s) occurred:
* aws_nat_gateway.spark-emr-nat-gw: Error waiting for NAT Gateway (nat-003ec858485ccadff) to become available: unexpected state 'failed', wanted target 'available'. last error: %!s(<nil>)
Terraform does not automatically rollback in the face of errors.
Instead, your Terraform state file has been partially updated with
any resources that successfully completed. Please address the error
above and apply again to incrementally change your infrastructure.
Possible causes
- Connectivity issues against AWS
- Unknown - Non deterministic
Solution:
- Execute
emr-deprovision - Execute
emr-provision
HERE Data SDK for Python-Core issues
Error installing using Pip on Windows because of GDAL
Follow these steps if you are getting an error related with GDAL or geopandas on Windows.
As suggested here, Download the wheels for GDAL, Fiona, Rasterio and Shapely. Make sure you choose the wheel files that match your architecture (64-bit) and Python version. If Gohlke mentions any prerequisites in his descriptions of those 4 packages, install the prerequisites now (there might be a C++ redistributable or something similar listed there).
Open a command prompt and change directories to the folder where you downloaded these 4 wheels.
In your terminal, install the 4 packages using wheel files in the order(GDAL, Fiona, rasterio, Shapely) by executing this sample command:
pip install GDAL‑3.1.2‑cp37‑cp37m‑win_amd64.whl
After all the 4 wheel packages are installed, retry installing the core module using the following command:
pip install --extra-index-url https://repo.platform.here.com/artifactory/api/pypi/analytics-pypi/simple/ here-nagini==1.12Create New Issue
If your issue is not reported, send an email to nocsupportchina@here.com.
Copy and paste the output of the following commands in the issue description:
conda infoconda env listwhich python