- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
HERE Data SDK for Python with Spark (DEPRECATED)
Data SDK for Python with Spark is a tool for Data Scientists who want to use Spark for large scale analysis of the platform data or who know they want to implement their solution in a pipeline and would prefer to use the same language/framework for analysis to simplify deployment to production.
The SDK uses the Sparkmagic extension for Jupyter in order to run spark jobs on Spark, either in local mode or in cluster mode:
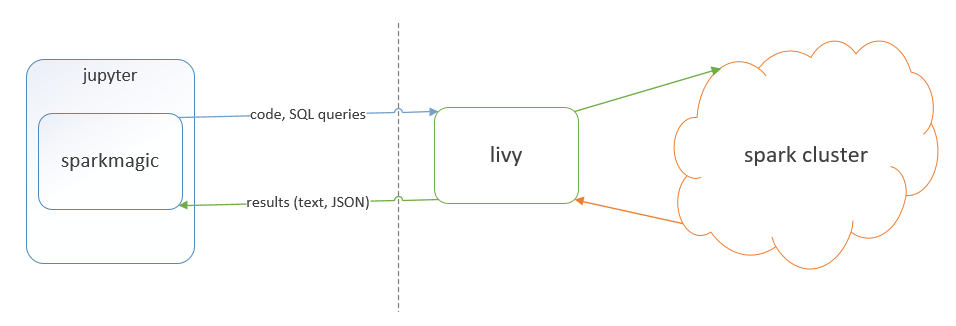
You can find the steps to install and configure the Data SDK for Python with Spark here.
Prerequisites
Installation
Data SDK for Python with Local Spark works only for Linux/MacOS. EMR Spark Cluster option is available for all platforms. To configure the SDK, do the following:
- Install and configure the Sparkmagic Extension.
- Choose the Livy Server Deployment that you need:
- Local Spark (Only for Linux/MacOS): See how to install and deploy Hadoop, Spark and Livy locally. This is the simplest and default option.
- EMR Spark Cluster (Optional): See how to deploy and connect to a remote EMR cluster if you want to run your jobs in there.